Virtualization, Cloud, Infrastructure and all that stuff in-between
My ramblings on the stuff that holds it all together
Category Archives: datacenter in a box
Using the VCE/vBlock concept to aid disaster relief in situations like the Haiti Earthquake
Posted by on January 16, 2010
Seeing the tragic events of the last couple of days in Haiti played out on the news spurred me into evolving some thinking that I had been working on, the sheer scale of infrastructure destruction left by the earthquake in Haiti is making it hard to get relief distributed via road, so airlifting and military assistance is the only realistic method of getting help around.
Whilst providing physical, medical, food and engineering relief is of paramount importance during a crisis, communications networks are vital to co-ordinate efforts between agencies, it is likely that whatever civil communications infrastructure, cell towers, landlines etc. are badly impacted by the earthquake so aid agencies rely on radio based systems, however as in the “business as usual” world the Internet can act as a well-understood common medium for exchanging digital information and services – if you can get access.
Crisis Camp is a very interesting and noble concept for gathering technically minded volunteers around the world to collaborate on producing useful tools for relief staff on the ground, missing people databases, geo-mapping mashups on Google Earth etc. using open source tools and donated people time makes this a free/low-cost soft-solution for relief agencies.
However, with the scale of infrastructure destruction in large disasters getting access to shared networks, bandwidth and cellular communications networks on the ground is likely to be difficult – in this post I propose a vendor neutral solution, whilst I reference the VCE/vBlock concept which is essentially an EMC/Cisco/VMware product line; the concept of a packaged, pre-built and quick to deploy infrastructure solution can apply equally to a single or multi-vendor “infrastructure care package” – standardisation and/or abstraction are the key to making it flexible (sound familiar to your day job?) by using virtual machines as the building blocks of useful services able to run on any donated/purchased/loaned hardware.
These care packages would typically be required for 2-3 months to aid disaster relief during the worst periods and whilst civil infrastructure is re-established. None of this stuff is free in the normal world, it’s a physical product, it’s tin, cables, margin and invoices but is flexible enough that it could be redeployed again and again as needs dictate, with my UN or DEC hat on this is a pool of shared equipment that can be sent around the world and deployed in 24hours to aid on the ground relief efforts, donated, loaned by vendors or sponsors.
What is it?

A bunch of low-power footprint commodity servers, storage and communications gear packed into a single, specialised shock-rack with a generator (gas/diesel/solar as available) and battery backup.
It makes heavy use of virtualization technologies to provide high-availability of data and services to work around individual equipment and/or rack failures due to damage or loss of power (generator out of fuel or localized aftershock etc.)
Because systems running to support relief operations typically will only be required for short term use, virtual appliances are an ideal platform, for example a pre-configured database cluster or web server farm, technologies like SpringSource can be used to deploy and bootstrap web applications around the infrastructure into virtual appliances.
Data storage and replication is achieved not using expensive hardware array based solutions but DAS storage within the blades (or shared disk stores) using virtual storage appliances like the HP Lefthand networks VSA or Celerra VSA or OpenFiler – allowing the use of cheap, commodity storage but achieving block-level replication between multiple storage locations via software – each blade uses storage within the same rack, if access to the storage fails it can be restarted on an alternative blade or an alternative rack (like the HA feature of vSphere)
These racks are deployed across a wide geographic area – creating a meshed wireless network using something like WiMax to handle inter-mesh and backhaul transit and local Femtocell/WiFi technology, providing 3 services
- private communications – for inter rack replication and data backhaul
- public data communications – wireless IP based internet access with a local proxy server/cache (backhaul via satellite or whatever is available – distributed across the mesh)
- local access to a public cellular system femtocell (GSM, or whatever the local standard is)

The availability/load balancing features of modern hypervisors like VMware’s HA/DRS and FT technology can re-start virtual machines to an alternative rack should one fail. Because the VSA technology replicates datastores between all racks at a block level using a p2p type protocol it’s always possible to restart a virtual appliance elsewhere within the infrastructure – but on a much wider scale and with a real-impact.

Ok, but what does it do?
Even if you were to establish a meshed communications network to assist with disaster relief activities on the ground, bandwidth and back-haul to the Internet or global public telecoms systems will be at a premium, chances are any high-bandwidth civil infrastructure will be damaged or degraded and satellite technology is expensive and can have limited bandwidth and high-latency.
The mesh system this solution could provide can give a layer of local caching and data storage, thinking particularly with the Google Maps type mashups people at Crisiscamp are discussing to help co-ordinate relief efforts that can require transferring a large amount of data – if you could get a local data cache of all the mapping information within the mesh transfer times would be drastically reduced.
this is really just a bunch of my thoughts on how you can take current hypervisor technology and build a p2p type private cloud infrastructure in a hurry, virtualization technology brings a powerful opportunity in that it can support a large number of services in a small power footprint; the more services that can be moved from dedicated hardware and run inside a virtual machine (for example a VoIP call manager, video conferencing system or GSM base station manager) mean less demand for scarce fuel and power resources on the ground; and virtualization brings portability – less dependence on a dedicated “black-box” that is hard to replace in the field, virtualization means you can use commodity x86 hardware, and have enough spares to keep things working or work around failures.
The technology to build this type of emergency service is available today with some tweaking. The key is having it in-place and ready to ship on a plane to wherever it is needed in the world, some more developed nations have this sort of service in-country for things like emergency cellular networks following hurricanes but it will need a lot of international co-operation to make this a reality on a global scale.
Whilst I’m not aware of any current projects by international relief agencies to build this sort of system I’d like to draw people’s attention to the possibilities.
The DEC are accepting donations for the Haiti earthquake relief fund at the following address.
or the international red-cross appeal here
Virtualization – the key to delivering "cloud based architecture" NOW.
Posted by on June 23, 2008
There is a lot of talk about delivering cloud or elastic computing platforms, a lot of CxO’s are taking this all in and nodding enthusiastically, they can see the benefits.. so make it happen!….yesterday.
Moving your services to the cloud, isn’t always about giving your apps and data to Google, Amazon or Microsoft.
You can build your own cloud, and be choosy about what you give to others. building your own cloud makes a lot of sense, it’s not always cheap but its the kind of thing you can scale up (or down..) with a bit of up-front investment, in this article I’ll look at some of the practical; and more infrastructure focused ways in which you can do so.

Your “cloud platform” is essentially an internal shared services system where you can actually and practically implement a “platform” team that operates and capacity plans for the cloud platform; they manage it’s availability and maintenance day-day and expansion/contraction.
You then have a number of “service/application” teams that subscribe to services provided by your cloud platform team… they are essentially developers/support teams that manage individual applications or services (for example payroll or SAP, web sites etc.), business units and stakeholders etc.
Using the technology we discuss here you can delegate control to them over most aspects of the service they maintian – full access to app servers etc. and an interface (human or automated) to raise issues with the platform team or log change requests.
I’ve seen many attempts to implement this in the physical/old world and it just ends in tears as it builds a high level of expectation that the server/infrastructure team must be able to respond very quickly to the end-“customer” the customer/supplier relationship is very different… regardless of what OLA/SLA you put in place.
However the reality of traditional infrastructure is that the platform team can’t usually react as quick as the service/application teams need/want/expect because they need to have an engineer on-site, wait for an order and a delivery, a network provisioning order etc. etc (although banks do seems to have this down quite well, it’s still a delay.. and time is money, etc.)
Virtualization and some of the technology we discuss here enable the platform team to keep one step ahead of the service/application teams by allowing them to do proper capacity planning and maintain a pragmatic headroom of capacity and make their lives easier by consolidating the physical estate they manage. This extra headroom capacity can be quickly back-filled when it’s taken up by adopting a modular hardware architecture to keep ahead of the next requirement.
Traditional infrastructure = OS/App Installations
- 1 server per ‘workload’
- Silo’d servers for support
- Individually underused on average = overall wastage
- No easy way to move workload about
- Change = slow, person in DC, unplug, uninstall, move reinstall etc.
- HP/Dell/Sun Rack Mount Servers
- Cat 6 Cables, Racks and structured cabling
The ideal is to have an OS/app stack that can have workloads moved from host A to host B; this is a nice idea but there are a whole heap of dependencies with the typlical applications of today (IIS/apache + scripts, RoR, SQL DB, custom .net applications). Most big/important line of business apps are monolithic and today make this hard. Ever tried to move a SQL installation from OLD-SERVER-A to SHINY-NEW-SERVER-B? exactly. *NIX better at this, but not that much better.. downtime required or complicated fail over.
This can all be done today, virtualization is the key to doing it – makes it easy to move a workload from a to b we don’t care about the OS/hardware integration – we standardise/abstract/virtualize it and that allows us to quickly move it – it’s just a file and a bunch of configuration information in a text file… no obscure array controller firmware to extract data from or outdated NIC/video drivers to worry about.
Combine this with server (blade) hardware, modern VLAN/L3 switches with trunked connections, and virtualised firewalls then you have a very compelling solution that is not only quick to change, but makes more efficient use of the hardware you’ve purchased… so each KW/hr you consume brings more return, not less as you expand.
Now, move this forward and change the hardware for something much more commodity/standardised
Requirement: Fast, Scalable shared storage, filexible allocation of disk space and ability to de-duplicate data, reduce overhead etc, thin provisioning.
Solution: SAN Storage, EMC Clariion, HP-EVA, Sun StorageTek, iSCSI for lower requirements, or storage over single Ethernet fabric – NetApp/Equalogic
Requirement: Requirement Common chassis and server modules for quick, easy rip and replace and efficient power/cooling.
Solution: HP/Sun/Dell Blades
Requirement: quick change of network configurations, cross connects, increase & decrease bandwidth
Solution: Cisco switching, trunked interconnects, 10Gb/bonded 1GbE, VLAN isolation, quick change enabled as beyond initial installation there are fewer requirements to send an engineer to plug something in or move it, Checkpoint VSX firewalls to allow delegated firewall configurations or to allow multiple autonomous business units (or customers) to operate from a shared, high bandwidth platform.
Requirement: Ability to load balance and consolidate individual server workloads
Solution: VMWare Infrastructure 3 + management toolset (SCOM, Virtual Centre, Custom you-specific integrations using API/SDK etc.)
Requirement: Delegated control of systems to allow autonomy to teams, but within a controlled/auditable framework
Solution: Normal OS/app security delegation, Active Directory, NIS etc. Virtual Center, Checkpoint VSX, custom change request workflow and automation systems which are plugged into platform API/SDK’s etc.
the following diagram is my reference architecture for how I see these cloud platforms hanging together
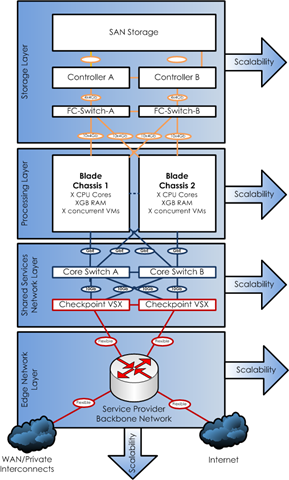
As ever more services move into the “cloud” or the “mesh” then integrating them becomes simpler, you have less of a focus on the platform that runs it – and just build what you need to operate your business etc.
In future maybe you’ll be able to use the public cloud services like Amazon AWS to integrate with your own internal cloud, allowing you to retain the important internal company data but take advantage of external, utility computing as required, on demand etc.
I don’t think we’ll ever get to.. (or want) to be 100% in a public cloud, but this private/internal cloud allows an organisation to retain it’s own internal agility and data ownership.
I hope this post has demonstrated that whilst, architecturally “cloud” computing sounds a bit out-there, you can practically implement it now by adopting this approach for the underlying infrastructure for your current application landscape.
A Closer look at Green IT and Microsoft’s new Container Data Centre in Chicago
Posted by on May 24, 2008
Link here – good visualisation about 10mins in of how their new Chicago data centre is laid out internally.
With virtualisation breaking the traditional hardware/OS ties; this is becoming an increasingly appealing way of managing commodity compute grid resources for large organisations. Mike makes some good points about the de-comissioning of servers on a large scale where you are adding 10’s of thousands on a regular basis – you need to take them out at some point too, and that’s time consuming. at this scale of operation It’s more efficient to make the the container and/or datacentre the field replaceable unit (as I discussed a while back) in this scenario.
Also interesting point that water consumption may be the next environmental touch paper for legislation and disclosure for IT shops.
New Microsoft Data Centre is Container Based
Posted by on April 2, 2008
Article here, it’s coming people!
Some interesting discussions on how you can measure the productivity of a container and come up with some common metrics to compare and contrast and handle charge-back.
Hot-Swap Datacentres
Posted by on February 11, 2008
There’s an interesting post over on Forrester research blog by James Staten. he’s talking some more about data centres in a container; making the data centre the FRU rather than a server or server components (Disk, PSU etc.).
This isn’t a new idea but it I’m sure the economics of scale currently mean this is currently suitable for the computing super-powers (Google, Microsoft – MS are buying them now!) – variances in local power/comms cost could soon force companies to adopt this approach rather than be tied to a local/national utility company and their power/comms pricing.
But just think if you are a large out-sourcing type company you typically reserve, build and populate data centres based on customer load, now this load can be variable; customers come and go (as much as you would like to keep them long-term this is becoming a commodity market and customer’s demand you are able to react quickly to changes in THEIR business model – which is typically why they outsource – they make it YOUR problem to service their needs).
It would make sense if you could dynamically grow and shrink your compute/hosting facility based on customer demand in this space – thats not so easy to do with a physical location as you are tied to it in terms of power availability/cost and lease period.
New suite build out at a typical co-lo company can take 1-2 months to establish networking, racks, power distribution, cabling, operational procedures etc. (and that’s not including physical construction if it’s a new building) – adopting the blackbox approach could significantly reduce the start-up time and increase your operational flexibility
Rather than invest in in-suite structured cabling, rack and reusable (or dedicated) server/blade infrastructures why not just have terminated power, comms and cooling connections and plug them in as required within a secured warehouse like space.



Photos from Sun Project Blackbox
You could even lease datacentre containers from a service provider/supplier to ensure there is no cap-ex investment required to host customers.
If your shiny new data centre is runs out of power then you could relocate it a lot easier (and cheaply) as it’s already transportable rather than tied to the physical building infrastructure; you are able to follow the cheapest power and comms – nationally or even globally.
As I’ve said before the more you virtualize the contents of your datacentre the less you care about what physical kit it runs on… you essentially reserve power from a flexible compute/storage/network “grid” – and that could be anything/anywhere.

