Virtualization, Cloud, Infrastructure and all that stuff in-between
My ramblings on the stuff that holds it all together
Category Archives: Fluid datacentre
Cloud Wars: VMWare vs Microsoft vs Google vs Amazon Clouds
Posted by on October 1, 2008
A short time ago in a data centre, far far away…..
All the big players are setting out their cloud pitches, Microsoft are set to make some big announcements at their Professional Developer Conference at the end of October and VMWare made their VDC-OS announcements at VMWorld a couple of weeks ago, Google have had their App Engine in beta for a while and Amazon AWS is pretty well established.
With this post I hope to give a quick overview of each, I’ll freely admit I’m more knowledgeable on the VMWare/Microsoft offerings… and I stand to be corrected on any assumptions I’ve made on Google/AWS based on my web reading.
So, What’s the difference between them…?
VMWare vCloud – infrastructure led play
VMWare come from the infrastructure space, to-date they have dominated the x86 virtualization market, they have some key strategic partnerships with storage and network vendors to deliver integrated solutions.
The VMWare VDC-OS pitch is about providing a flexible underlying architecture through servers, network and storage virtualisation. why? because making everything ‘virtual’ makes for quick reconfiguration – reallocating resource from one service to another is a configuration/allocation change rather than requiring an engineer visit (see my other post on this for more info)
because VMWare’s pitch is infrastructure led it has a significant practical advantage in that it’s essentially technology agnostic (as long as it’s x86 based) you, or a service provider have the ability to build and maintain an automated birth–>death bare ‘virtual metal’ provisioning and lifecycle system for application servers/services as there is no longer a tight dependency for everything on physical hardware, cabling etc
There is no one size fits all product in this space so a bespoke solution based around a standard framework tool like Tivoli, SMS, etc. is typically required depending on organisational/service requirements.
No re-development is necessarily required to move your applications into a vCloud (hosted or internal) you just move your VMWare virtual machines to a different underlying VDC-OS infrastructure, or you use P2V, X2V tools like Platespin to migrate to a VDC-OS infrastructure.
In terms of limitations – apps can’t necessarily scale horizontally (yet) as they are constrained by their traditional server based roots. The ability to add a 2nd node doesn’t necessarily make your app scale – there are all kinds of issues around state, concurrency etc. that the application framework needs to manage.
VMWare are building frameworks to build scale-out provisioning tools – but this would only work for certain types of applications and is currently reactive unless you build some intelligence into the provisioning system.
Scott Lowe has a good round-up of VDC-OS information here & VMWare’s official page is online here
Google AppEngine– pure app framework play
An application framework for you to develop your apps within – it provides a vastly parallel application and storage framework – excellent for developing large applications (i.e Google’s bread & butter)
Disadvantage is it’s a complete redevelopment of you applications into Google compatible code, services & frameworks. You are tied into Google services – you can’t (as I understand it) take your developed applications elsewhere without significant re-development/porting.
The Google AppEngine blog is here
Microsoft Cloud Services Hosted Application stack & Infrastructure play
An interesting offering, they will technically have the ability to host .net applications from a shared hosting service, as well as integrating future versions of their traditional and well established office/productivity applications into their cloud platform; almost offering the subscription based/Software+Services model they’ve been mooting for a long time.
Given Microsoft’s market current dominance, they are very well positioned to make this successful as large shops will be able to modify existing internal .net services and applications to leverage portions of their cloud offering.
With the future developments of Hyper-V Microsoft will be well positioned to offer an infrastructure driven equivalent of VMWare’s VDC-OS proposition to service and support migration from existing dedicated Windows and Linux servers to an internal or externally hosted cloud type platform.
David Chou at Microsoft has a good post on Microsoft and clouds here
Amazon Web Services – established app framework with canned virtualization
the AWS platform provides a range of the same sort of functionality as Google AppEngine with SimpleDB, SQS and S3 but with the recently announced ability to run Windows within their EC2 cloud makes for an interesting offering with the existing ability to pick & choose from Linux based virtual machine instances.
I believe EC2 makes heavy use of Xen under the hood; which I assume is how they are going to be delivering the Windows based services, EC2 also allows you to choose from a number of standard Linux virtual machine offerings (Amazon Machine Image, AMI).
This is an interesting offering, allowing you to develop your applications into their framework and possibly port or build your Linux/Windows application services into their managed EC2 service.
Same caveat applies though, your apps and virtual machines could be tied to the AWS framework – so you loose your portability without significant re-engineering. on the flip-side they do seem to have the best defined commercial and support models and have been well established for a while with the S3 service.
Amazon’s AWS blog is available here
Conclusion
Microsoft & VMWare are best positioned to pick up businesses from the corporate’s who will likely have a large existing investment in code and infrastructure but are looking to take advantage of reduced cost and complexity by hosting portions of their app/infrastructure with a service-provider.
Microsoft & VMWare offerings easily lend themselves to this internal/external cloud architecture as you can build your own internal cloud using their off-the-shelf technology, something that isn’t possible with AWS or Google. This is likely to be the preferred model for most large businesses who need to retain ownership of data and certain systems for legal/compliance reasons.
leveraging virtualization and commercial X2V or X2X conversion tools will make transition between internal and external clouds simple and quick – which gives organisations a lot of flexibility to operate their systems in the most cost/load-effective manner as well as retain detailed control of the application/server infrastructure but freed up from the day-day hardware/capacity management roles.
AWS/Google are ideal for Web 2.0 ,start-ups and the SME sector where there is typically no existing or large code-base investment that would need to be leveraged. For a greenfield implementation these services offer low start-up cost and simple development tools to build applications that would be complicated & expensive to build if you had to worry about and develop supporting infrastructure without significant up-front capital backing.
AWS/Google are also great for people wanting to build applications that need to scale to lots of users, but without a deep understanding of the required underlying infrastructure, whilst this is appealing to corporate’s I think the cost of porting and data ownership/risk issues will be a blocker for a significant amount of time.
Google Apps are a good entry point for the SME/start-up sector and startups, and could well draw people into building AppEngine services as the business grows in size and complexity, so we may see a drift towards this over time. Microsoft have a competing model and could leverage their established brand to win over customers if they can make the entry point free/cheap and cross-platform compatible, lots of those SME/start-ups are using Mac’s or Netbooks for example.
Virtualization – the key to delivering "cloud based architecture" NOW.
Posted by on June 23, 2008
There is a lot of talk about delivering cloud or elastic computing platforms, a lot of CxO’s are taking this all in and nodding enthusiastically, they can see the benefits.. so make it happen!….yesterday.
Moving your services to the cloud, isn’t always about giving your apps and data to Google, Amazon or Microsoft.
You can build your own cloud, and be choosy about what you give to others. building your own cloud makes a lot of sense, it’s not always cheap but its the kind of thing you can scale up (or down..) with a bit of up-front investment, in this article I’ll look at some of the practical; and more infrastructure focused ways in which you can do so.

Your “cloud platform” is essentially an internal shared services system where you can actually and practically implement a “platform” team that operates and capacity plans for the cloud platform; they manage it’s availability and maintenance day-day and expansion/contraction.
You then have a number of “service/application” teams that subscribe to services provided by your cloud platform team… they are essentially developers/support teams that manage individual applications or services (for example payroll or SAP, web sites etc.), business units and stakeholders etc.
Using the technology we discuss here you can delegate control to them over most aspects of the service they maintian – full access to app servers etc. and an interface (human or automated) to raise issues with the platform team or log change requests.
I’ve seen many attempts to implement this in the physical/old world and it just ends in tears as it builds a high level of expectation that the server/infrastructure team must be able to respond very quickly to the end-“customer” the customer/supplier relationship is very different… regardless of what OLA/SLA you put in place.
However the reality of traditional infrastructure is that the platform team can’t usually react as quick as the service/application teams need/want/expect because they need to have an engineer on-site, wait for an order and a delivery, a network provisioning order etc. etc (although banks do seems to have this down quite well, it’s still a delay.. and time is money, etc.)
Virtualization and some of the technology we discuss here enable the platform team to keep one step ahead of the service/application teams by allowing them to do proper capacity planning and maintain a pragmatic headroom of capacity and make their lives easier by consolidating the physical estate they manage. This extra headroom capacity can be quickly back-filled when it’s taken up by adopting a modular hardware architecture to keep ahead of the next requirement.
Traditional infrastructure = OS/App Installations
- 1 server per ‘workload’
- Silo’d servers for support
- Individually underused on average = overall wastage
- No easy way to move workload about
- Change = slow, person in DC, unplug, uninstall, move reinstall etc.
- HP/Dell/Sun Rack Mount Servers
- Cat 6 Cables, Racks and structured cabling
The ideal is to have an OS/app stack that can have workloads moved from host A to host B; this is a nice idea but there are a whole heap of dependencies with the typlical applications of today (IIS/apache + scripts, RoR, SQL DB, custom .net applications). Most big/important line of business apps are monolithic and today make this hard. Ever tried to move a SQL installation from OLD-SERVER-A to SHINY-NEW-SERVER-B? exactly. *NIX better at this, but not that much better.. downtime required or complicated fail over.
This can all be done today, virtualization is the key to doing it – makes it easy to move a workload from a to b we don’t care about the OS/hardware integration – we standardise/abstract/virtualize it and that allows us to quickly move it – it’s just a file and a bunch of configuration information in a text file… no obscure array controller firmware to extract data from or outdated NIC/video drivers to worry about.
Combine this with server (blade) hardware, modern VLAN/L3 switches with trunked connections, and virtualised firewalls then you have a very compelling solution that is not only quick to change, but makes more efficient use of the hardware you’ve purchased… so each KW/hr you consume brings more return, not less as you expand.
Now, move this forward and change the hardware for something much more commodity/standardised
Requirement: Fast, Scalable shared storage, filexible allocation of disk space and ability to de-duplicate data, reduce overhead etc, thin provisioning.
Solution: SAN Storage, EMC Clariion, HP-EVA, Sun StorageTek, iSCSI for lower requirements, or storage over single Ethernet fabric – NetApp/Equalogic
Requirement: Requirement Common chassis and server modules for quick, easy rip and replace and efficient power/cooling.
Solution: HP/Sun/Dell Blades
Requirement: quick change of network configurations, cross connects, increase & decrease bandwidth
Solution: Cisco switching, trunked interconnects, 10Gb/bonded 1GbE, VLAN isolation, quick change enabled as beyond initial installation there are fewer requirements to send an engineer to plug something in or move it, Checkpoint VSX firewalls to allow delegated firewall configurations or to allow multiple autonomous business units (or customers) to operate from a shared, high bandwidth platform.
Requirement: Ability to load balance and consolidate individual server workloads
Solution: VMWare Infrastructure 3 + management toolset (SCOM, Virtual Centre, Custom you-specific integrations using API/SDK etc.)
Requirement: Delegated control of systems to allow autonomy to teams, but within a controlled/auditable framework
Solution: Normal OS/app security delegation, Active Directory, NIS etc. Virtual Center, Checkpoint VSX, custom change request workflow and automation systems which are plugged into platform API/SDK’s etc.
the following diagram is my reference architecture for how I see these cloud platforms hanging together
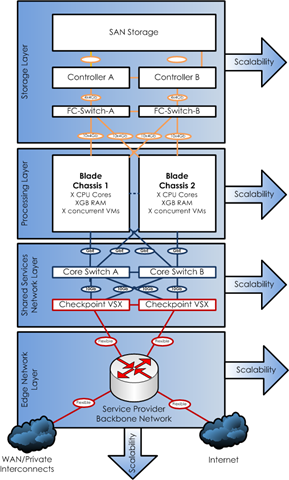
As ever more services move into the “cloud” or the “mesh” then integrating them becomes simpler, you have less of a focus on the platform that runs it – and just build what you need to operate your business etc.
In future maybe you’ll be able to use the public cloud services like Amazon AWS to integrate with your own internal cloud, allowing you to retain the important internal company data but take advantage of external, utility computing as required, on demand etc.
I don’t think we’ll ever get to.. (or want) to be 100% in a public cloud, but this private/internal cloud allows an organisation to retain it’s own internal agility and data ownership.
I hope this post has demonstrated that whilst, architecturally “cloud” computing sounds a bit out-there, you can practically implement it now by adopting this approach for the underlying infrastructure for your current application landscape.
A Closer look at Green IT and Microsoft’s new Container Data Centre in Chicago
Posted by on May 24, 2008
Link here – good visualisation about 10mins in of how their new Chicago data centre is laid out internally.
With virtualisation breaking the traditional hardware/OS ties; this is becoming an increasingly appealing way of managing commodity compute grid resources for large organisations. Mike makes some good points about the de-comissioning of servers on a large scale where you are adding 10’s of thousands on a regular basis – you need to take them out at some point too, and that’s time consuming. at this scale of operation It’s more efficient to make the the container and/or datacentre the field replaceable unit (as I discussed a while back) in this scenario.
Also interesting point that water consumption may be the next environmental touch paper for legislation and disclosure for IT shops.
P2V Backup & Disaster Recovery
Posted by on February 20, 2008
There is a new site here (disclaimer: it does seem to be promoting a commercial service, but has some useful information that has been put into the public domain); describing some methods to roll your own P2V backup approach; I’ve not read in detail yet; but looks like Frane Borozan has solved some of the challenges I’ve encountered in the past automating the Free VMWare Convertor tool.
When I get some time I will revisit my build a better test lab series (and update it!) I hope to be able to integrate some of Frane’s ideas.
Thanks to Techhead for passing on the link; we worked together on the platform underlying the Build a better test lab series and he did a lot of work on the P2V and post-P2V automation tasks – he’s got a lot of handy scripts for doing this on an HP platform
Virtualized DR is going to be big this year; I have a long line of customers with this high on their list of priorities… Both for cross site 100% VMWare implementations and for the ability to backup/restore physical platforms to VMWare grid in a DR situation.
It just makes so much sense; no delay whilst racking & stacking recovery kit or problems restoring to different hardware etc. your admin’s can even do it from home – which can have some significant advantages in the event of a natural disaster like Katrina or floods like we had over the last couple of years in the UK
PlateSpin Forge is something we are seriously looking at as well as Symantec Backup Exec System Recovery Server Edition (who win a prize for extending the longest, most annoying product name! despite acquiring it from Veritas).
Will be an interesting year; I’m sure Sungard and all those recovery centre facilities will be moving to a grid/resource rental model rather than pure rack/floor space and retained hardware on-contract.
Hot-Swap Datacentres
Posted by on February 11, 2008
There’s an interesting post over on Forrester research blog by James Staten. he’s talking some more about data centres in a container; making the data centre the FRU rather than a server or server components (Disk, PSU etc.).
This isn’t a new idea but it I’m sure the economics of scale currently mean this is currently suitable for the computing super-powers (Google, Microsoft – MS are buying them now!) – variances in local power/comms cost could soon force companies to adopt this approach rather than be tied to a local/national utility company and their power/comms pricing.
But just think if you are a large out-sourcing type company you typically reserve, build and populate data centres based on customer load, now this load can be variable; customers come and go (as much as you would like to keep them long-term this is becoming a commodity market and customer’s demand you are able to react quickly to changes in THEIR business model – which is typically why they outsource – they make it YOUR problem to service their needs).
It would make sense if you could dynamically grow and shrink your compute/hosting facility based on customer demand in this space – thats not so easy to do with a physical location as you are tied to it in terms of power availability/cost and lease period.
New suite build out at a typical co-lo company can take 1-2 months to establish networking, racks, power distribution, cabling, operational procedures etc. (and that’s not including physical construction if it’s a new building) – adopting the blackbox approach could significantly reduce the start-up time and increase your operational flexibility
Rather than invest in in-suite structured cabling, rack and reusable (or dedicated) server/blade infrastructures why not just have terminated power, comms and cooling connections and plug them in as required within a secured warehouse like space.



Photos from Sun Project Blackbox
You could even lease datacentre containers from a service provider/supplier to ensure there is no cap-ex investment required to host customers.
If your shiny new data centre is runs out of power then you could relocate it a lot easier (and cheaply) as it’s already transportable rather than tied to the physical building infrastructure; you are able to follow the cheapest power and comms – nationally or even globally.
As I’ve said before the more you virtualize the contents of your datacentre the less you care about what physical kit it runs on… you essentially reserve power from a flexible compute/storage/network “grid” – and that could be anything/anywhere.

