Virtualization, Cloud, Infrastructure and all that stuff in-between
My ramblings on the stuff that holds it all together
Category Archives: Datacentre
Silent Data Corruption in the Cloud and building in Data Integrity
Posted by on January 20, 2011
I was passed a link to a very interesting article on-line about silent data corruption on very large data sets, where corruption creeps undetected into the data read and written by an application over time.
Errors are common in reading from all media and this would normally be trapped by storage subsystem logic and handled lower down the stack but as these increase in complexity and the data they store vastly increases in scale this could become a serious problem as there could be bit-errors not being trapped by disk/RAID subsystems that are passed on unknown to the requesting application as a result of firmware bugs or faulty hardware – typically these bugs manifest themselves in a random manner or by edge-case users with unorthodox demands.
All hardware has a error/transaction rate – in systems up until now this hasn’t really been too much of a practical concern as you run a low chance of hitting one, but – as storage quantities increase into multiple Tb of data this chance increases dramatically. A quick scan round my home office tallys about 16Tb of on-line SATA storage, by the article’s extrapolation on numbers this could mean I have 48 corrupt files already.
This corruption is likely to be single-bit in nature and maybe it’s not important for certain file formats – but you can’t be sure, I can think of several file formats where flipping a single bit renders them unreadable in the relevant application.
Thinking slightly wider, if you are the end-user “victim” of some undetected bit-flipping what recourse do you have when that 1 flips to a 0 to say your life insurance policy doesn’t cover that illness you have just found you have – “computer says no”?
This isn’t exclusively a “cloud problem” it applies to any enterprise storing a significant amount of data without any application level logic checks, but it is compounded in the cloud world where it’s all about a centralised storage of data, applications and code, multi-tenanted and highly consolidated, possibly de-duplicated and compressed where possible.
In a market where cost/Gb is likely to be king providers will be looking to keep storage costs low, using cheap-er disk systems – but making multiple copies of data for resilience (note, resilience is different from integrity) – this could introduce further silent bit corruptions that are propagated across multiple instances as well as increasing the risk of exposure to a single-bit error due to the increased number of transactions involved.
In my view, storage hardware and software already does a good job of detecting and resolving these issues and will scale the risks/ratios with volumes stored. But, if you are building cloud applications maybe it’s time to consider a check summing method when storing/fetching data from your cloud data stores to be sure – that way you have a platform (and provider)-independent method of providing data integrity for your data.
Any such check summing will carry a performance penalty, but that’s the beauty of cloud – scale on demand, maybe PaaS providers will start to offer a web-service to offload data check summing in future?
Check summing is an approach for data reliability, rather than security but at a talk I saw at a Cloudcamp last year; a group were suggesting building DB field-level encryption into your cloud application, rather than relying on infrastructure to protect your data by physical and logical security or disk or RDBMS-level encryption (as I see several vendors are touting) build it into your application and only ever store encrypted assets there – then even if your provider is compromised all they hold (or leak) is already encrypted database contents – you as the end-user still retain full control of the keys and controls.
Combine this approach with data reliability methods and you have a good approach for data integrity in the cloud.
Virtualization – the key to delivering "cloud based architecture" NOW.
Posted by on June 23, 2008
There is a lot of talk about delivering cloud or elastic computing platforms, a lot of CxO’s are taking this all in and nodding enthusiastically, they can see the benefits.. so make it happen!….yesterday.
Moving your services to the cloud, isn’t always about giving your apps and data to Google, Amazon or Microsoft.
You can build your own cloud, and be choosy about what you give to others. building your own cloud makes a lot of sense, it’s not always cheap but its the kind of thing you can scale up (or down..) with a bit of up-front investment, in this article I’ll look at some of the practical; and more infrastructure focused ways in which you can do so.

Your “cloud platform” is essentially an internal shared services system where you can actually and practically implement a “platform” team that operates and capacity plans for the cloud platform; they manage it’s availability and maintenance day-day and expansion/contraction.
You then have a number of “service/application” teams that subscribe to services provided by your cloud platform team… they are essentially developers/support teams that manage individual applications or services (for example payroll or SAP, web sites etc.), business units and stakeholders etc.
Using the technology we discuss here you can delegate control to them over most aspects of the service they maintian – full access to app servers etc. and an interface (human or automated) to raise issues with the platform team or log change requests.
I’ve seen many attempts to implement this in the physical/old world and it just ends in tears as it builds a high level of expectation that the server/infrastructure team must be able to respond very quickly to the end-“customer” the customer/supplier relationship is very different… regardless of what OLA/SLA you put in place.
However the reality of traditional infrastructure is that the platform team can’t usually react as quick as the service/application teams need/want/expect because they need to have an engineer on-site, wait for an order and a delivery, a network provisioning order etc. etc (although banks do seems to have this down quite well, it’s still a delay.. and time is money, etc.)
Virtualization and some of the technology we discuss here enable the platform team to keep one step ahead of the service/application teams by allowing them to do proper capacity planning and maintain a pragmatic headroom of capacity and make their lives easier by consolidating the physical estate they manage. This extra headroom capacity can be quickly back-filled when it’s taken up by adopting a modular hardware architecture to keep ahead of the next requirement.
Traditional infrastructure = OS/App Installations
- 1 server per ‘workload’
- Silo’d servers for support
- Individually underused on average = overall wastage
- No easy way to move workload about
- Change = slow, person in DC, unplug, uninstall, move reinstall etc.
- HP/Dell/Sun Rack Mount Servers
- Cat 6 Cables, Racks and structured cabling
The ideal is to have an OS/app stack that can have workloads moved from host A to host B; this is a nice idea but there are a whole heap of dependencies with the typlical applications of today (IIS/apache + scripts, RoR, SQL DB, custom .net applications). Most big/important line of business apps are monolithic and today make this hard. Ever tried to move a SQL installation from OLD-SERVER-A to SHINY-NEW-SERVER-B? exactly. *NIX better at this, but not that much better.. downtime required or complicated fail over.
This can all be done today, virtualization is the key to doing it – makes it easy to move a workload from a to b we don’t care about the OS/hardware integration – we standardise/abstract/virtualize it and that allows us to quickly move it – it’s just a file and a bunch of configuration information in a text file… no obscure array controller firmware to extract data from or outdated NIC/video drivers to worry about.
Combine this with server (blade) hardware, modern VLAN/L3 switches with trunked connections, and virtualised firewalls then you have a very compelling solution that is not only quick to change, but makes more efficient use of the hardware you’ve purchased… so each KW/hr you consume brings more return, not less as you expand.
Now, move this forward and change the hardware for something much more commodity/standardised
Requirement: Fast, Scalable shared storage, filexible allocation of disk space and ability to de-duplicate data, reduce overhead etc, thin provisioning.
Solution: SAN Storage, EMC Clariion, HP-EVA, Sun StorageTek, iSCSI for lower requirements, or storage over single Ethernet fabric – NetApp/Equalogic
Requirement: Requirement Common chassis and server modules for quick, easy rip and replace and efficient power/cooling.
Solution: HP/Sun/Dell Blades
Requirement: quick change of network configurations, cross connects, increase & decrease bandwidth
Solution: Cisco switching, trunked interconnects, 10Gb/bonded 1GbE, VLAN isolation, quick change enabled as beyond initial installation there are fewer requirements to send an engineer to plug something in or move it, Checkpoint VSX firewalls to allow delegated firewall configurations or to allow multiple autonomous business units (or customers) to operate from a shared, high bandwidth platform.
Requirement: Ability to load balance and consolidate individual server workloads
Solution: VMWare Infrastructure 3 + management toolset (SCOM, Virtual Centre, Custom you-specific integrations using API/SDK etc.)
Requirement: Delegated control of systems to allow autonomy to teams, but within a controlled/auditable framework
Solution: Normal OS/app security delegation, Active Directory, NIS etc. Virtual Center, Checkpoint VSX, custom change request workflow and automation systems which are plugged into platform API/SDK’s etc.
the following diagram is my reference architecture for how I see these cloud platforms hanging together
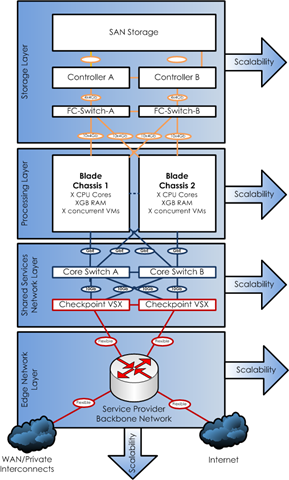
As ever more services move into the “cloud” or the “mesh” then integrating them becomes simpler, you have less of a focus on the platform that runs it – and just build what you need to operate your business etc.
In future maybe you’ll be able to use the public cloud services like Amazon AWS to integrate with your own internal cloud, allowing you to retain the important internal company data but take advantage of external, utility computing as required, on demand etc.
I don’t think we’ll ever get to.. (or want) to be 100% in a public cloud, but this private/internal cloud allows an organisation to retain it’s own internal agility and data ownership.
I hope this post has demonstrated that whilst, architecturally “cloud” computing sounds a bit out-there, you can practically implement it now by adopting this approach for the underlying infrastructure for your current application landscape.
A Closer look at Green IT and Microsoft’s new Container Data Centre in Chicago
Posted by on May 24, 2008
Link here – good visualisation about 10mins in of how their new Chicago data centre is laid out internally.
With virtualisation breaking the traditional hardware/OS ties; this is becoming an increasingly appealing way of managing commodity compute grid resources for large organisations. Mike makes some good points about the de-comissioning of servers on a large scale where you are adding 10’s of thousands on a regular basis – you need to take them out at some point too, and that’s time consuming. at this scale of operation It’s more efficient to make the the container and/or datacentre the field replaceable unit (as I discussed a while back) in this scenario.
Also interesting point that water consumption may be the next environmental touch paper for legislation and disclosure for IT shops.
VMWare Server Performance – A Practical Example
Posted by on April 19, 2008
The following screen dump is from an HP DL380G5 server that runs all the core infrastructure under VMWare Server (the free one) for a friend’s company which I admin sometimes.
It is housed in some co-lo space and runs the average range of Windows servers used by a small but global business, Exchange SQL, Windows 2003 Terminal Services.
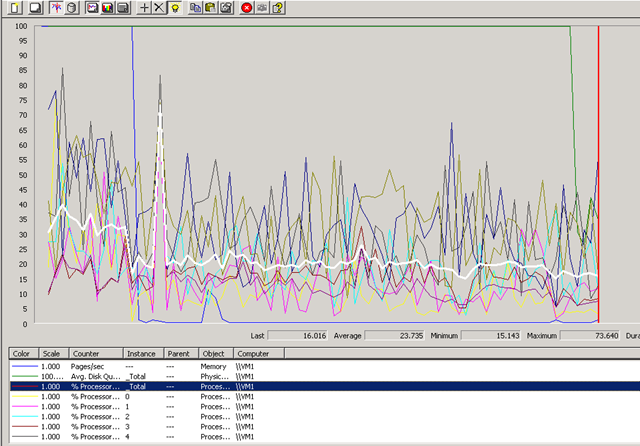
As a result of some planned (but not very well communicated!) power maintenance the whole building lost power earlier today, when it was restored I grabbed the following screenshot as the 15 or so Virtual Machines automatically booted.
interesting to note that all the VM’s had been configured to auto-start with the guest OS, meaning there wasn’t any manual intervention required, even though it was a totally dirty shutdown for both the host and guest OS’es (No UPS, as the building and suite is supposed to have redundant power feeds to each rack – in this instance the planned maintenance was on the building wiring so required taking down all power feeds for a 5 yearly inspection..)
There are no startup delay settings in the free version of VMWare Server so they all start at the same time, interesting to note the following points..
The blue line that makes a rapid drop is the pages/second counter, and the 2nd big drop (green) is the disk queue length. the hilighted (white) line is the overall %CPU time, note the sample frequency was 15 seconds on this perfmon.
After it had settled down, I took the following screenshot, it hardly breaks a sweat during its working day. there are usually 10-15 concurrent users on this system from around the world (access provisioned via an SSL VPN device) and a pretty heavily used Exchange mail system.
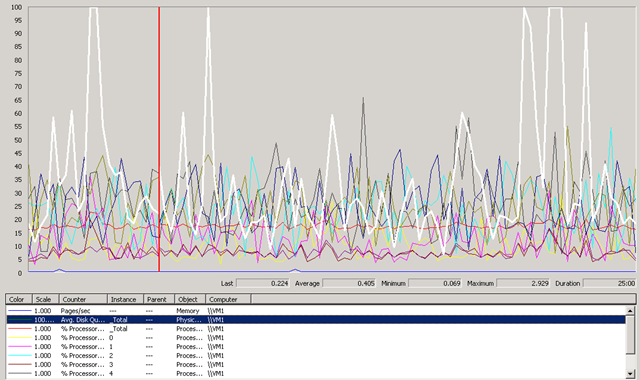
The box is an HP DL380 G5 with 2 x quad core CPUs (8 cores in total) and 16Gb of RAM, it has 8 x 146Gb 15k HDDs in a single RAID 5 set + hot-spare, it was purchased in early 2007 and cost c.£8,000 (UK Prices)
It runs Windows 2003 Enterprise Edition x64 edition with VMWare Server 1.0.2 (yes, its an old build.. but if it ain’t broke..) and they have purchased multiple w2k3 ent-edition licences to take advantage of the virtualisation use-rights to cover the installed virtual OS’es.
It’s been in-place for a year and hardly ever has to be touched, its rock-solidly available and the company have noticed several marked improvements since they P2V’d their old servers onto this platform, as follows;
- No hardware failures – moving from lots of low-end servers (Dell) and desktops to a single box (10:1 consolidation)
- The DL380 has good redundancy built in, but it’s also backed up with a h/w maintenence contract, and they also have a spare cold-standby server to resume service from backups if data is lost.
- Less noise, the old servers were dotted around their old offices in corners, racks etc – this is the main thing they liked!
- Simple access anywhere – using a Juniper SA2000 SSL VPN, its easy to get secure access from anywhere
- Less reliance on physical offices and cheap DSL-grade data communications, now the servers are hosted on the end of a reliable, data centre class network link with an SLA to back it up. if an individual office looses its ADSL connection, no real issue – people pick up their laptop(s) and work from home/starbucks etc.
- Good comms are cheaper in data centres than in your branch offices (usually)
Hopefully this goes to show the free version of VMWare’s server products can work almost as well if budget is a big concern, ESX would definitely give some better features and make backup easier, they are considering upgrading and combining with something like Veeam Backup to handle failover/backup.
How does an HP Fibre Channel Virtual Connect Module Work?
Posted by on April 9, 2008
Techhead and I have spent a lot of time recently scratching our heads over how and where fibre channel SAN connections go in a c7000 blade chassis.
If you don’t know, a FC-VC module looks like this, and you install them in redundant pairs in adjacent interconnect bays at the rear of the chassis.

You then patch each of the FC Ports into a FC switch.
The supported configuration is one FC-VC Module to 1 FC switch (below)
![clip_image002[6]](https://vinf.net/wp-content/uploads/2008/04/clip-image0026.jpg)

Connecting one VC module to more than one FC switch is unsupported (below)
![clip_image002[8]](https://vinf.net/wp-content/uploads/2008/04/clip-image0028.jpg)

So, in essence you treat each VC module as terminating all HBA Port 1’s and the other FC-VC module as terminating all HBA Port 2’s.
The setup we had:
- A number of BL460c blades with dual-port Qlogic Mezzanine card HBAs.
- HP c7000 Blade chassis with 2 x FC-VC modules plugged into interconnect bay 3 & 4 (shown below)


The important point to note is that whilst you have 4 uplinks on each FC-VC module that does not mean you have 2 x 16Gb/s connection “pool or trunk” that you just connect into.
Put differently if you unplug one, the overall bandwidth does not drop to 12Gb/s etc. it will disconnect a single HBA port on a number of servers and force them to failover to the other path and FC-VC module.
It does not do any dynamic load balancing or anything like that – it is literally a physical port concentrator which is why it needs NPIV to pass through the WWN’s from the physical blade HBAs.
There is a concept of over-subscription, in the Virtual Connect GUI that’s managed by setting the number of uplink ports used.
Most people will probably choose 4 uplink ports per VC module, this is 4:1 oversubscription, meaning each FC-VC port (and there are 4 per module) has 4 individual HBA ports connected to it, if you reduce the numeber of uplinks you increase the oversubscription (2 uplinks = 8:1 oversubscription, 1 uplink = 16:1 oversubscription)

Which FC-VC Port does my blade’s HBA map to?
The front bay you insert your blade into determines which individual 4Gb/s port it maps to and shares with other blades) on the FC-VC module, its not just a virtual “pool” of connections, this is important when you plan your deployment as it can affect the way failover works.
the following table is what we found from experimentation and a quick glance at the “HP Virtual Connect Cookbook” (more on this later)
| FC-VC Port | Maps to HBA in Blade Chassis Bay, and these ports are also shared by.. |
| Bay3-Port 1, Bay-4-Port 1 | 1,5,11,15 |
| Bay3-Port 2, Bay-4-Port 2 | 2,6,12,16 |
| Bay3-Port 3, Bay-4-Port 3 | 3,7,9,13 |
| Bay3-Port 4, Bay-4-Port 4 | 4,8,10,14 |

Each individual blade has a dual port HBA, so for example the HBA within the blade in bay 12 maps out as follows
HBA Port 1 –> Interconnect Bay 3, Port 2
HBA Port 2 –> Interconnect Bay 4, Port 2
Looking at it from a point of a single SAN attached Blade – the following diagram is how it all should hook together
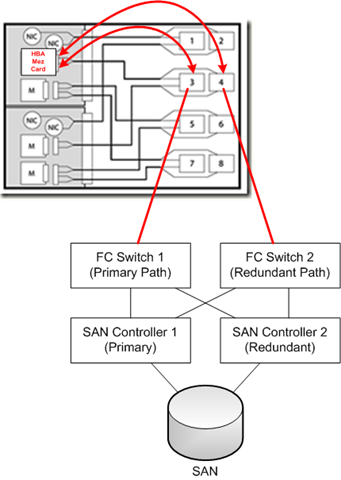
Path Failover
Unplugging an FC cable from bay 3, port 4 will disconnect one of the HBA  connections to all of the blades in bays 4,8,10 and 14 and force the blade’s host OS to handle a failover to its secondary path via the FC-VC module in bay 4.
connections to all of the blades in bays 4,8,10 and 14 and force the blade’s host OS to handle a failover to its secondary path via the FC-VC module in bay 4.
A key take away from this is that your blade hosts still need to run some kind of multi-pathing software, like MPIO or EMC PowerPath to handle the failover between paths – the FC-VC modules don’t handle this for you.

FC Loading/Distribution
A further point to take away from this is that if you plan to fill your blade chassis with SAN attached blades, each with an HBA connected to a pair of FC-VC modules then you need to plan your bay assignment carefully based on your server load.
Imagine if you were to put heavily used SAN-attached VMWare ESX Servers in bays 1,5,11 and 15 and lightly used servers in the rest of the bays then you will have a bottleneck as your ESX blades will all be contending with each other for a single pair of 4Gb/s ports (one on each of the FC-VC modules) whereas if you distributed them into (for example) bays 1,2,3,4 then you’ll spread the load across individual 4Gb/s FC ports.
Your approach of course may vary depending on your requirements, but I hope this post has been of use.

There is a very, very useful document from HP called the HP Virtual Connect Fibre Channel Cookbook that covers all this in great detail, it doesn’t seem to be available on the web and the manual and online documentation don’t seem to have any of this information, if you want a copy you’ll need to contact your HP representative and ask for it.
New Microsoft Data Centre is Container Based
Posted by on April 2, 2008
Article here, it’s coming people!
Some interesting discussions on how you can measure the productivity of a container and come up with some common metrics to compare and contrast and handle charge-back.
HP iLo Very Slow for Installing an OS
Posted by on February 27, 2008
A bit of a disappointment; we’re trying to do a WinPE 2.0 CD/DVD based installation for our Windows 2003/2008 standard blade servers in an HP c7000 enclosure.
Installing from a .ISO image presented to the iLo via the virtual media applet is dog-slow (5-10 times slower than from a physical CD/DVD- why is this? – surely its technically possible to make this access run faster and GigE chipsets are cheap-as these days. I’ve been through every combination of switching/duplex/port config and even via a cable directly into the Blade OA.
The same issue seems to manifest itself on traditional rack mount HP servers – the iLo just isn’t fast enough to make this a workable solution, unless you are really patient.
I know we could use the RDP and do it as a PXE type installation over the network to each blade, but this doesn’t really achieve what I want…
Most customers maintain an OoB (Out of Band) network to which all of the management interfaces (iLo, DRAC, etc.) are connected to. the reasoning for this is obvious; if you loose your main core switching network you can get access via a totally different physical network and path to assist in troubleshooting.
For this same reasoning I would like to use this method to build servers from a master boot CD/DVD image, you can present a .ISO image to a server via the virtual media applet on the iLo. We have a fully end-end build process that sets up the HP array controllers, flashes BIOS and installs the OS and drivers etc. from a CD/DVD.
We just update the boot CD .ISO file as required and its flexible and it doesn’t rely on any deployment infrastructure (PXE server, RDP server etc.) so we can port it between customers and data centres, VM’s and physical machines and do a bare-metal builds without requiring any build/network infrastructure in place.
This isn’t just limited to a Windows OS – I tried the same with an ESX installation; took over an hour (compared to 5-10 mins from a local CD)
Mmmm, Big, Really Big Cisco Switches
Posted by on February 11, 2008

